Moving ML Inference from the Cloud to the Edge
In this blog post, I investigate running Machine Learned (ML) inference computation as close as possible to where the model input data is generated on a user's device at the edge. There are several definitions of "Edge," but for me, Edge computations cover inference computations on the user device, in the Browser, and compute at the front of Cloud regions in Content Delivery Networks (CDNs). Examples of computing infrastructure on the Edge are Lambda@Edge from AWS and Cloudflare Workers from Cloudflare.
In this blog post, I will cover a Holiday project of mine where the goal was to run ML Inference in the Browser with an NLP model for text classification.
Motivation for Inference at the Edge
There are, as I see it, three primary reasons for running ML inference on the user device instead of in the Cloud:
- Improved Privacy — User-sensitive data does not leave the user's device. The ML inference is performed on the user's device, and data used as model input does not cross the network. Thus, no sensitive user data in transit means that the potential for intercepting the data in transit is eliminated. Furthermore, since the data never leaves the user's device, no data is compromised if the inference service provider experiences a data breach. Also, updating (training) the model weights on the device is a promising direction from a privacy perspective.
- Eliminating network latency— Moving the model input data over the network from the user device where the data is created for inference in the Cloud requires a reliable high-speed network. Network latency on the high-speed network is broadly a function of the speed of light and the data that must be transferred. Even sending a single network packet back and forth from a device in the us-east to a cloud region in the us-west is easily 150ms round-trip. Unless the Cloud inference API is replicated across many Cloud regions, the device to cloud network latency is a show stopper for real-time ML inference where the user is waiting for the model's response. In addition, running inference on the user device adds the possibility to run without any network connectivity.
- Improved scalability and reduced cost — Since the inference runs on the user's device, the ML inference serving architecture is genuinely serverless. There are no server-side inference servers to manage. Scaling up the user base from thousands to millions of users does not significantly increase the Cloud bill. By moving the inference computation to the user device, the user gets improved privacy and a more responsive app in return for the client-side computing, which effectively is paid by the user.
There are other compelling reasons as well. For example, see this excellent blog post from Chip Huyen on the topic of edge computing.
Cloud-based ML Inference
The current pattern for deploying ML models in the Browser has been to perform a network call with the user-provided data to a server-side inference service which invokes the model with the data on the cloud side.
One concrete example of a server-side inference service is the Huggingface inference API for Natural Language Processing (NLP) models. In the example below, I invoke the Huggingface inference API with a short text input and measure the end to end response using the curl timing support :
curl -w "\nTotal time %{time_total}s\n" 'https://api-inference.huggingface.co/models/bergum/xtremedistil-emotion' \-H 'Connection: keep-alive' \-H 'content-type: application/json' \-H 'Accept: */*' \--data-raw $'{"inputs":"Happy New Year\u0021"}' \--compressed
Executing the above will return the inference result and the timing information added by the curl -w option
[[{"label":"LABEL_0","score":0.009859317913651466},{"label":"LABEL_1","score":0.9782078862190247},{"label":"LABEL_2","score":0.007416774518787861},{"label":"LABEL_3","score":0.00019748960039578378},{"label":"LABEL_4","score":0.0002684995415620506},{"label":"LABEL_5","score":0.004049977287650108}]]Total time 0.439802s
So just above 400 ms to run an inference with the cloud-based API from a client located in Trondheim, Norway. The actual server-side model inference is just single-digit milliseconds, but the overall latency is driven by the network latency. In the above call, most of the latency is caused by TLS handshake when setting up a new connection. Still, even with an existing live established connection, the round trip network latency is typically 150 ms. Since the Huggingface inference API is not replicated across multiple Cloud regions, the end-to-end latency is dominated by the network latency for most users, except the ones close to the cloud region to which the endpoint is deployed.
In the above example, the input to the ML model was text, with a small data footprint size. On the other hand, ML models which accept video or image data in which input size is considerably larger than text uploading the data to a cloud-based inference service becomes impossible. Consider, for example, Tesla's self-driving Machine Learned Model. It would be impossible to upload video and image data from the car sensors to a server-side inference service for self-driving inference in real-time.
For server-side inference, the cost of scaling with the user-generated inference traffic can become significant. For example, in the above model which is served on a CPU with an inference latency of around 10 ms, one CPU core would be able to serve about 100 inferences/s. Scaling to 10 000 inferences per second would require 100 CPU cores, which roughly equals a yearly cost of 40,000$ just in EC2 instances. With client-side inference, the Cloud computing cost would be 0$.
Building blocks for Edge ML Inference
To be able to perform real-time inference on the device, there are several technologies or building blocks needed:
- Model Delivery One needs to deliver the ML model to the user's device. Model delivery could be on-demand as the user visits a web page, or by a direct app or extension download, or embedded with software installed on the user device. For real-time on-demand online inference, the model needs to be delivered to the device before the inference stage (obviously). Content Delivery Networks (CDNs) companies like Cloudfare can help accelerate the model delivery as these CDN companies allow the serving of both static files and dynamic compute (e.g workers/functions) in multiple regions across the world. An ML model is stored as a binary file, which can be compressed for improved network latency, e.g., using zstd, which has an excellent compression ratio and is fast to decompress on the client device. Furthermore, the model can be cached on the user device, so that the delivery is limited to bootstrapping a new user session or a server-side model refresh.
- ML Feature Processing Pipeline on Device — Once the model is delivered, we need a way to produce and read the input data and produce the model's feature input. To perform inference in the Browser one must implement the real-time ML feature pipeline using Javascript for inference in the Browser (Or use web assembly).
- ML Model Inference Invoking the model and capturing the result, and displaying the result to the user,
Text Classification at the edge
Back in October, the Microsoft ONNX-Runtime team announced the availability of ONNX-Runtime with webassembly-simd support in this blog post. Since I've used ONNX-Runtime a lot at work for Vespa.ai this seemed like a very interesting technology direction. Enabling SIMD instructions in the Browser could speed up inference significantly. Webassmebly also makes it possible to write the ML feature pipeline in a language like Rust, then compile it to webassembly. See for example https://www.rust-lang.org/what/wasm.
Based on the above blog post I started a project this holiday to see how fast inference of an NLP BERT model in the Browser could be. I have also wanted to learn more about frontend development so it seemed like a perfect fit.
I decided to build a text classification model trained on the Emotion dataset. Emotion is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise. The dataset has 16,000 labeled examples on which the model was trained with. At work, I've used several miniature BERT models which are CPU-friendly for text ranking.
This time I chose https://huggingface.co/microsoft/xtremedistil-l6-h256-uncased which only has 13M parameters, but rivals the larger BERT base model accuracy on GLUE and SQuAD-v2. A smaller model means a lower network footprint when delivering the model to the Browser and significantly faster inference (9x compared to the original BERT-base model).
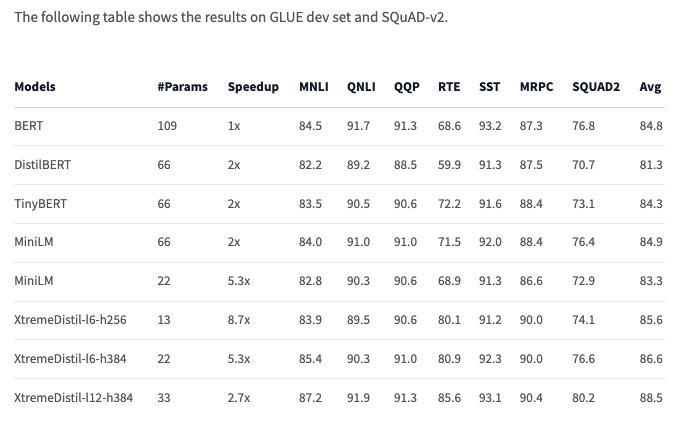
The model was fine-tuned using Google Colab, details in this notebook. Using float32 weights the model had an accuracy of 92.65% on the test set (the holdout set). The model is saved after training on the HF hub. The notebook also demonstrates how to export the fine-tuned model to ONNX format for serving with ONNX-Runtime web. Another benefit of using a smaller model is that training is faster, training for 24 epochs (24*16000) only took a few minutes on GPU.
React App + Javascript feature processing + Inference with ONNX-Runtime web
To deploy the app I needed to choose a Javascript framework for the frontend. I've heard great things about React. In addition, I needed to host the model and React app, so I chose to use Cloudfare Pages. Since Cloudflare Pages only allow serving files up to 25MB, I used quantization to reduce the model size by changing the model weight precision type from float32 to int8. Quantization reduces the model file size to 13MB, but the accuracy is unfortunately negatively impacted. The accuracy drop is a friendly reminder always to check accuracy impact on the downstream task when altering the model parameters. The notebook demonstrates validating the model accuracy using ONNX-Runtime with both float32 (default) and int8 quantized weights.
The Javascript API for making inference with ONNX-Runtime web is straightforward and similar to the python API (which uses native bindings):
- Inference API usage and feature input processing https://github.com/jobergum/browser-ml-inference/blob/main/src/inference.js
- React App Logic https://github.com/jobergum/browser-ml-inference/blob/main/src/App.js
- In addition, I had to find a BERT subword tokenizer to tokenize the text input into BERT subword vocabulary ids. The Tokenizer used in this project is a slightly modified version of the one from Tensorflow Javascript library.
By using Cloudfare pages, the model delivery is optimized as it is cached close to the user. Working with Cloudfare pages was great. Create a new pages project and point to the GitHub or GitLab repository (Which can be private), and CF takes care of the deployment. Push a change to the main branch in git, and Cloudfare takes care of the deployment to the worldwide regions. To display the inference result, I used https://www.react-google-charts.com/, which was relatively easy to work with and display the inference scores for the six emotions the model classifies.
Putting it together — Meet aiserv.cloud
Cloudflare Pages also allows adding CNAME DNS forwarding, so I registered aiserv.cloud to point to the CF page endpoint. The screenshot below is the frontend UI. I'm not a designer, sorry.

Immediately as a user visits aiserv.cloud, the Javascript code will start downloading the BERT vocabulary (30 KB) and the BERT model (13 MB) asynchronously. When the textarea input changes based on the user text input, the text is tokenized, and the model is invoked and the predicted emotions are displayed with scores. The front end also displays the inference latency in milliseconds to test performance on multiple devices.

So in this case, the same text input as we used for the cloud-Based Huggingface endpoint for the same model, it took 4.1 ms running the model in a browser on a Macbook pro (2017 model), while the cloud-based inference took 400ms, so that is a 100x overall improvement.
Conclusion
Running ML Inference in the Browser is perfectly doable for the smaller distilled BERT models, and there is a huge latency and cost improvement if the size of the model can be kept in check. To summarize, I used:
- Cloudflare Pages to deliver this app and model with CDN
- ONNX Runtime Web for Model Inference
- Huggingface for model hosting and training API
- Google Colab for model training
- Live demo at https://aiserv.cloud/.
The React app, model, and everything are open-sourced in the https://github.com/jobergum/browser-ml-inference repository.
